
Abstract
Dynamic scene reconstruction and novel view synthesis are fundamental to next-generation visual intelligence applications such as virtual reality, robotics, and digital twins. However, high-fidelity reconstruction of complex, time-varying scenes from arbitrary viewpoints remains a significant challenge. Existing dynamic 3DGS methods suffer from computational inefficiency, since they model all Gaussians as dynamic components. While recent decomposition-based approaches address this issue, they still struggle with degraded reconstruction quality and prolonged training times. To mitigate these limitations, we propose a novel dynamic reconstruction framework built upon an efficient static-dynamic decomposition strategy using a Feed-Forward Gaussian Splatting encoder and an optical flow model. By eliminating redundant computations on static regions, our method achieves state-of-the-art performance, outperforming existing baselines across rendering quality, training and rendering speeds, and storage efficiency. Notably, on Neural 3D dataset, our framework requires only 10 minutes for training and achieves a rendering speed of over 700 FPS on a single NVIDIA RTX 5090 GPU at resolution of 1352×1014. Furthermore, our decomposition strategy eliminates the need for COLMAP preprocessing and enables deterministic initialization, thereby enhancing both efficiency and reproducibility.
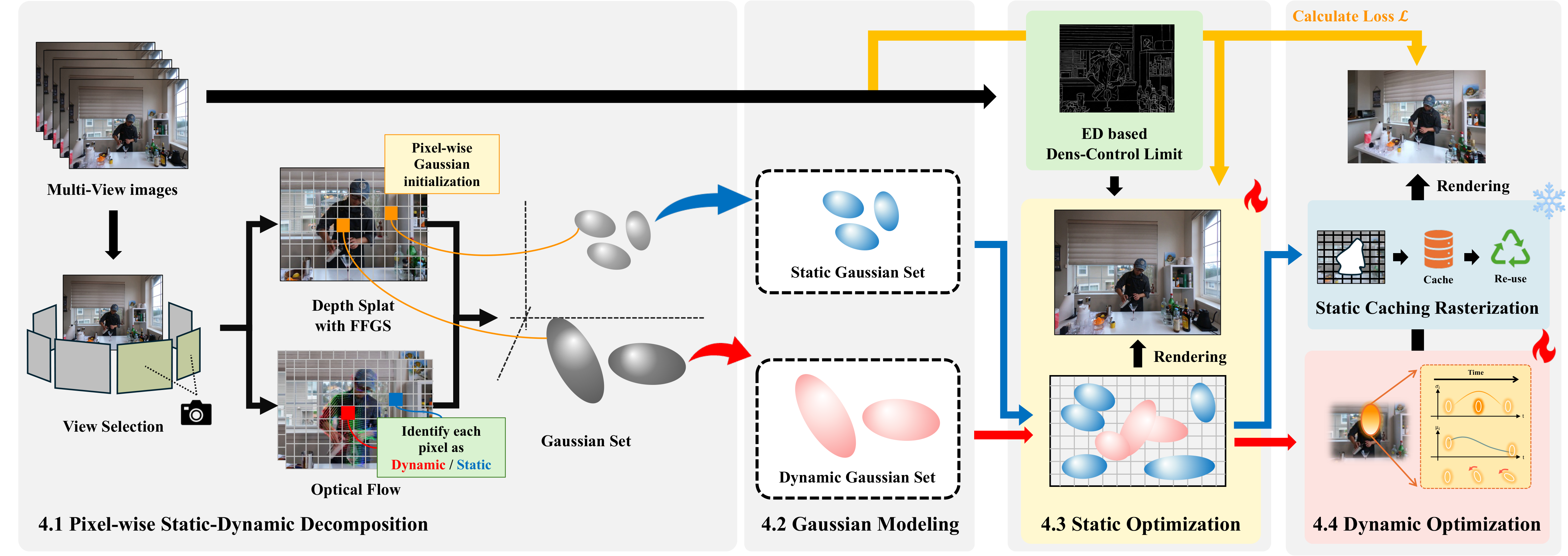
Method
Brief description of the proposed method. Explain the key components and how they work together.
Results
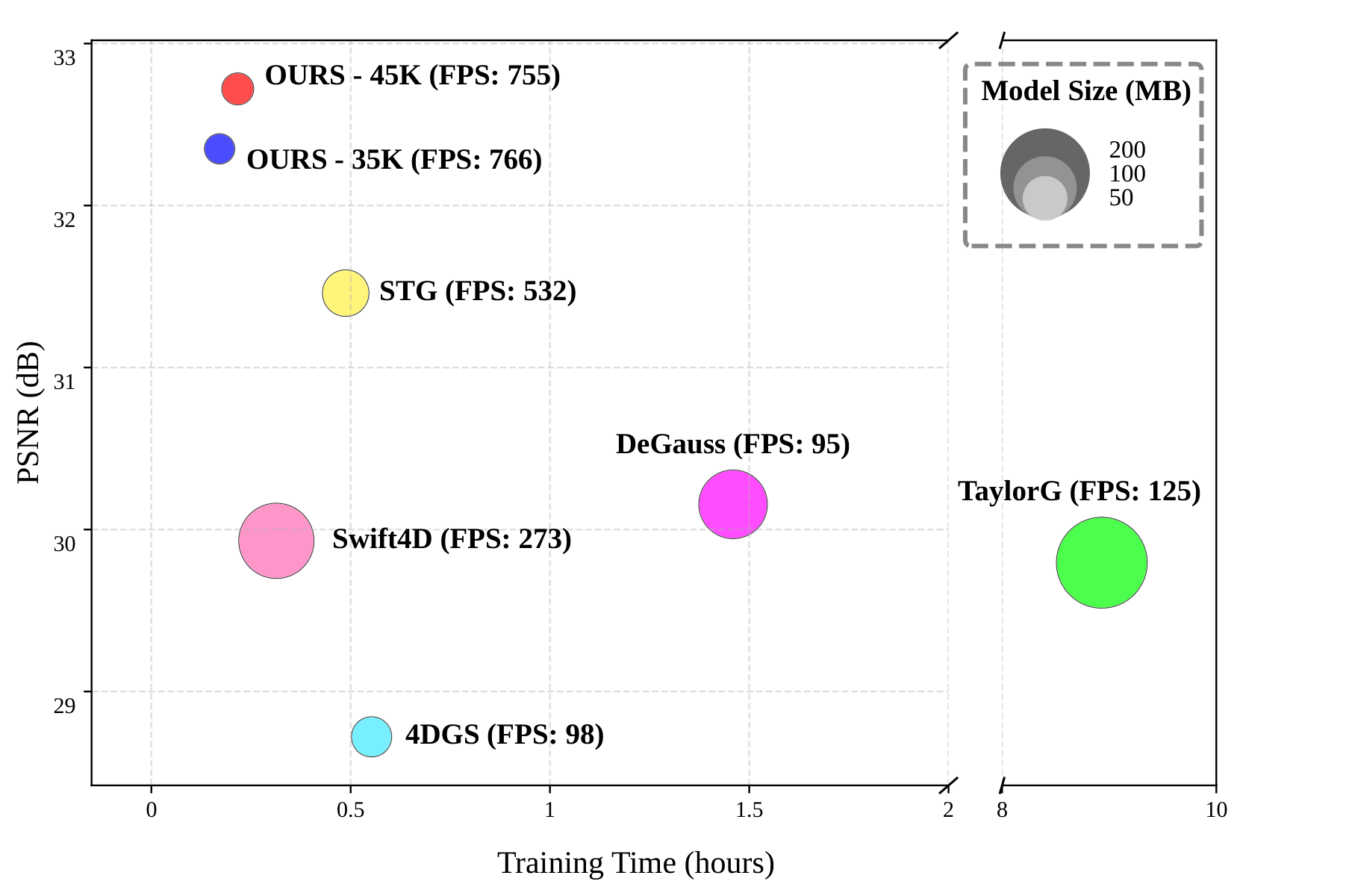
Table 1. Quantitative comparison on Neural 3D dataset. In the Colmap column, SA denotes 'Sparse point cloud for All frames' and D0 denotes 'Dense point cloud for the 0th frame'. Following the original STG paper, which reports training six models for every 50 frames, we provide results for both the multi-model approach and a single-model approach trained on the full 300-frame sequence.
| Method | Colmap | Preproc. Time ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | Train Time ↓ | FPS ↑ | Storage ↓ | Frames |
|---|---|---|---|---|---|---|---|---|---|
| 4DGS | D0 | 6 mins | 28.72 | 0.9306 | 0.1528 | 33 mins | 98 | 40.3 | 300 |
| STG | SA | 25 mins | 31.75 | 0.9473 | 0.1423 | 2h 43mins | 683 | 127.5 | 50×6 |
| STG | SA | 25 mins | 31.46 | 0.9432 | 0.1474 | 29 mins | 532 | 54.0 | 300 |
| TaylorG | SA | 25 mins | 29.80 | 0.9558 | 0.1597 | 9 hours | 125 | 205.7 | 300 |
| Swift4D | D0 | 18 mins | 29.93 | 0.9383 | 0.1370 | 19 mins | 273 | 141.2 | 300 |
| DeGauss | D0 | 6 mins | 30.16 | 0.9357 | 0.1430 | 1h 27mins | 95 | 117.5 | 300 |
| OURS-35K | ✗ | 4 sec | 32.35 | 0.9480 | 0.1295 | 10 mins | 766 | 23.1 | 300 |
| OURS-45K | ✗ | 4 sec | 32.72 | 0.9502 | 0.1221 | 14 mins | 755 | 23.7 | 300 |